library(tidyverse)
library(emuR)7 The Emu query language
7.1 Objective and preliminaries
The objective of this chapter is to show how to use the Emu query language for hierarchically structured annotations. The query language takes a bit of practice to get used to, but it’s a highly practical tool and making the effort is worth it!
We assume that you already have an R project called ipsR. If this is not the case, please go back and follow the preliminaries chapter.
We’ll load the usual libraries:
In this chapter we will make use of the demonstration database that we also saw in Chapter 2. We will download and store the demo database as we did in that chapter:
create_emuRdemoData(dir = tempdir())
path.ae <- file.path(tempdir(), "emuR_demoData", "ae_emuDB")
ae <- load_emuDB(path.ae, verbose = FALSE)
summary(ae)── Summary of emuDB ────────────────────────────────────────────────────────────Name: ae
UUID: 0fc618dc-8980-414d-8c7a-144a649ce199
Directory: C:\Users\rasmu\AppData\Local\Temp\RtmpM3VLFZ\emuR_demoData\ae_emuDB
Session count: 1
Bundle count: 7
Annotation item count: 736
Label count: 844
Link count: 785 ── Database configuration ──────────────────────────────────────────────────────── SSFF track definitions ── name columnName fileExtension fileFormat
dft dft dft ssff
fm fm fms ssff ── Level definitions ── name type nrOfAttrDefs attrDefNames
Utterance ITEM 1 Utterance;
Intonational ITEM 1 Intonational;
Intermediate ITEM 1 Intermediate;
Word ITEM 3 Word; Accent; Text;
Syllable ITEM 1 Syllable;
Phoneme ITEM 1 Phoneme;
Phonetic SEGMENT 1 Phonetic;
Tone EVENT 1 Tone;
Foot ITEM 1 Foot; ── Link definitions ── type superlevelName sublevelName
ONE_TO_MANY Utterance Intonational
ONE_TO_MANY Intonational Intermediate
ONE_TO_MANY Intermediate Word
ONE_TO_MANY Word Syllable
ONE_TO_MANY Syllable Phoneme
MANY_TO_MANY Phoneme Phonetic
ONE_TO_MANY Syllable Tone
ONE_TO_MANY Intonational Foot
ONE_TO_MANY Foot Syllable As seen in the summary(), the database has an EVENT-type level called Tone in which annotations are defined by single points in time, one SEGMENT-type level called Phonetic with start and end times, and several ITEM-type levels which inherit times from the Phonetic level, e.g. Syllable and Word. The link definitions summary shows a rich annotation structure that produces the tree-like structure seen in Figure 7.1 for the first utterance (note that only a single path through the hierarchy is shown). You should see the same if you serve() the database and go to the hierarchy view.
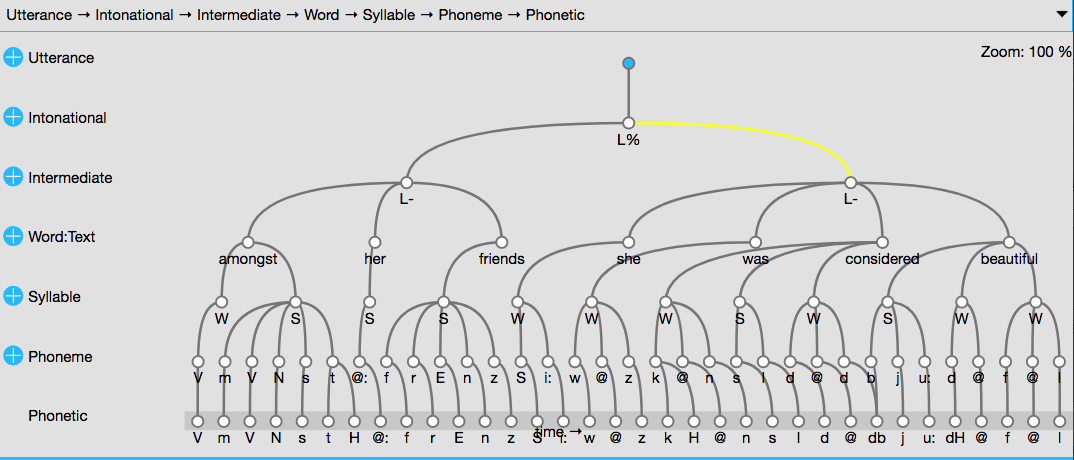
ae.7.2 First steps with the query language
7.2.1 A simple query
The function for computing queries is called query(). You will have seen this function in previous chapters, but this is where we describe how it works. query() needs at least two arguments: the name of the database and the query itself, e.g.
V <- query(ae, "Phonetic == V")The expression [Phonetic == V] is a legal expression in the EMU Query Language (EQL) (more on this below) and can be translated into prose as: return those annotations in the Phonetic level that contain the label V and only the label V“ (V is the SAMPA for English equivalent to IPA /ʌ/, i.e. the vowel in words like cut).
7.2.2 The object returned by query()
query() finds three instances of labels equaling V in the Phonetic level. Recall that we stored the output of our query() in the object V. We remove the db_uuid column from the resulting data frame here so the results are easier to read.
V %>% select(-db_uuid)This is an object of the type tibble, similar to a data frame, containing one row per segment. We’ll refer to the objects returned by query() as segment lists. Segment lists contain the following information:
labelscontains annotations or sequenced annotations concatenated by->; more on this belowstartcontains start times in millisecondsendcontains end times in millisecondsdb_uuid(removed above) is a unique identifier of the EMU databasesessioncontains the session name where the segment is foundbundlecontains the file bundle name where the segment is foundlevelcontains the name of the annotation level which has been searchedattributecontains the name of the attribute which has been searchedtypecontains the annotation level type, i.e.ITEM,EVENT, orSEGMENT(see Chapter 2)sample_startcontains the position of the first sample in the sound filesample_endcontains the position of the last sample in the sound filesample_ratecontains the sample rate of the sound file (i.e. thestartandendcolumns can be calculated by dividingsample_startorsample_endbysample_rate)
The tibble also contains the columns start_item_id, end_item_id, start_item_seq_idx, and end_item_seq_idx, which are used internally by emuR to query the JSON files where the annotations are stored.
It is straightforward to access information from the segment lists, by accessing these columns:
V$labels; V$start; V$end[1] "V" "V" "V"[1] 187.425 340.175 1943.175[1] 256.925 426.675 2037.425Alternatively, using tidyverse-style functions:
V %>% pull(labels)[1] "V" "V" "V"V %>% pull(start)[1] 187.425 340.175 1943.175V %>% pull(end)[1] 256.925 426.675 2037.425It also makes it easy to e.g. calculate the durations of all intervals:
V$end - V$start[1] 69.50 86.50 94.25Alternatively in tidyverse style:
V %>%
mutate(dur = end - start) %>%
pull(dur)[1] 69.50 86.50 94.25In the above example, v is a segment list with start and end times for each item because Phonetic is a SEGMENT-type level. EVENT-type levels can be queried as well – in this case the structure of the tibble that is returned is exactly the same, except only 0s are returned in the end column, since the annotations mark unique events in time. For example, here is a ‘segment list’ of all tones showing just a few columns:
tones <- query(ae, "Tone =~ .*")
tones %>% select(labels, start, end, bundle)7.2.3 Inherited times
Annotations in ITEM-type levels that either have no times or that inherit times from another level can be can queried in the same way. As the following shows, Phonetic is a SEGMENT-type level, and Phoneme is an ITEM-type annotation level without intrinsic time information.
list_levelDefinitions(ae)If we query() ae as above but searching the Phoneme level rather than the Phonetic level for V, we get the following results:
V_phoneme <- query(ae, "Phoneme == V")
V_phoneme %>% select(-db_uuid)Despite Phoneme being an ITEM-type level, the output has start and end times! In fact, they are identical to the start and end times of our previous query:
V_phoneme$start; V$start[1] 187.425 340.175 1943.175[1] 187.425 340.175 1943.175This is because times in the Phoneme level are in this case inherited from the Phonetic level (see Chapter 2 for a reminder why this is the case). The calculation of inherited times can be time-consuming in larger segment lists and it can be turned off with the calcTimes argument like so:
V_phoneme2 <- query(ae,
"[Phoneme == V]",
calcTimes = FALSE)
V_phoneme2 %>% select(-db_uuid)In this case, all values in the start and end columns are returned as NA (= Not Available).
7.2.4 Requerying
The function requery_hier() allows for segment lists (or ‘event lists’) to be created for an annotation level linked to a previously created segment list. In the above case, the annotation level of the segment list V_phoneme was Phoneme which is linked directly to the Syllable and Phonetic levels.
Since the annotations are hierarchically structured (Syllable is linked to Word, Word is linked to the Intermediate level etc.) and Phoneme is near the bottom of this structure, this makes it possible to query just about any other level (see Figure 7.1). Using the function requery_hier(), we can use our existing segment list V_phoneme to query the annotations at another level during those same times. Below, we requery Text, which is an attribute of Word, to get the orthographic representation of words which appear in V_phoneme.
t.s <- requery_hier(ae,
seglist = V_phoneme,
level = "Text")
t.s %>% select(-db_uuid)The above is a requery looking “upstream” to a level that dominates Phoneme. A downstream query makes a segment list of all annotations that are found delimited by ->. This means that we can use the segment list t.s that we just created to get a list of all anotations at the Phoneme level for those words:
requery_hier(ae,
seglist = t.s,
level = "Phoneme") %>%
select(-db_uuid)As another example, we can use query() to make a segment list of all words, and requery() to find out which of these words are associated with tones. This is possible because the Word level (and therefore also its attribute Text) is linked to the Tone level via the Syllable level, as we saw above when calling list_linkDefinitions(ae) and in Figure 7.1 above.
all.s <- query(ae, "Text =~ .*")
requery_hier(ae,
seglist = all.s,
level = "Tone") %>%
select(-db_uuid)A lot of these rows are marked NA – this is because there is no annotation in the Tone level associated with that word, i.e. the word has no pitch accent.
The function requery_seq() is used for finding annotations that sequentially precede or follow those in an existing segment list. In contrast to the requery_hier() function, the segment lists returned from requery_seq() are always from the same annotation level as the segment list being requeried. The argument offset, which takes a positive or negative integer, finds following annotations if the integer is positive, and preceding annotations if the integer is negative. Thus to find the phonemes that immediately follow those of the segment list V_phoneme, we do the following:
requery_seq(emuDBhandle = ae,
seglist = V_phoneme,
offset = 1) %>%
select(-db_uuid)To find the phonemes 2 positions prior to those in V_phoneme, the command should be the same but with offset = -2.
requery_seq(emuDBhandle = ae,
seglist = V_phoneme,
offset = -2)Error in requery_seq(emuDBhandle = ae, seglist = V_phoneme, offset = -2): 1 of the requested sequence(s) is/are out of boundaries.
Set parameter 'ignoreOutOfBounds=TRUE' to get residual result segments that lie within the bounds.This command fails! This is because in some cases there are no annotations two positions prior to those in V_phoneme. As the error message tells us, we can get around this problem with the additional argument ignoreOutOfBounds. Let’s try that.
requery_seq(emuDBhandle = ae,
seglist = V_phoneme,
offset = -2,
ignoreOutOfBounds = TRUE) %>%
select(-db_uuid)This returns NA in the first row, because there are no annotations two positions prior to this segment.
A further variation on the requery_seq() function is to include the argument length, which takes a positive integer. This finds a sequence of annotations of the specified length at a given offset position. For example, the following makes a segment list that extends from 1–3 annotations to the right relative to the segment list V_phoneme:
requery_seq(emuDBhandle = ae,
seglist = V,
offset = 1,
length = 3) %>%
select(-db_uuid)7.3 More complex queries
So far, we have only covered how query() can be used to find exact matches of a character string. The functionality of the EQL is a fair bit broader, and in the rest of this chapter, we give an overview of what it can do.
query() takes an argument also named query. This argument takes a string, meaning that the actual query must always be placed in quotation marks " ". Any query can be placed within square brackets [ ], and as we will see below, this is sometimes necessary. The query must minimally include the name of an annotation level and a representation of an annotation – these can be a character or string of characters to search for in that annotation level, but can also be regular expression. More on this below.
7.3.1 EQL operators
In the examples above, we found annotations in the Phonetic or Phoneme levels that were exactly equal to V with the following:
query(ae, "Phonetic == V") %>% select(-db_uuid)== is an operator indicating equality. For backwards compatibility with earlier versions of emuR, a single = is also allowed and gives the same result:
query(ae, "Phonetic = V") %>% select(-db_uuid)Searches can also be made for everything except V by using the inequality operator != (“is not equal to”) as below:
query(ae, "Phonetic != V") %>% select(-db_uuid)This returns every segment in the Phonetic level except those with V labels.
For finding matches that are not exact, e.g. for finding part of a string, the matching operator =~ is used. A special but very useful case for this operator is to find all annotations in an annotation level. This can be achieved with the combined regular expression .*. In regular expressions, . is a wildcard that can stand for any character, and * means that it can be repeated any number of times. The query Phonetic =~ .* thus means “return strings with any characters of any length from the Phonetic level”, i.e., “return everything from the Phonetic level”.
query(ae, "Phonetic =~ .*") %>% select(-db_uuid)This fits, because our query() for exact matches of V had a 3 rows, our query() including everything but V had 250 rows, and our query for everything has 253 rows!
We could also use the matching operator for e.g. finding all annotations at the Text level that begin with a. We do this with the query Text =~ '^a.*', which searches for all words where the first character (this is indicated with ^) is a. (Note that any queries using the ^ operator requires the matching string to be enclosed with quotation marks ' ').
query(ae, "Text =~ '^a'") %>% select(-db_uuid)There is a corresponding non-matching operator !~, which we could use for finding all words that don’t start with a using the same syntax:
query(ae, "Text !~ '^a'") %>% select(-db_uuid)The | operator (the “or”-operator) can be used to search for several annotations in one go. For example, searching for instances of either m or n in the Phonetic level can be accomplished with the following:
query(ae, "Phonetic == m | n") %>% select(-db_uuid)| can be used with an arbitrary number of strings:
query(ae, "Phonetic =~ ai | ei | oi") %>% select(-db_uuid)7.3.2 Features
It is possible to define features and then query them. The definition of features is accomplished with the function add_attrDefLabelGroups(). For the existing ae database some features have already been defined. To see these for the Phonetic level, we can use the function list_attrDefLabelGroups():
list_attrDefLabelGroups(ae,
levelName = "Phonetic",
attributeDefinitionName = "Phonetic")This means that the strings found in the Phonetic level have already been classified according to some features. For example the feature nasal, which covers the annotations m and n. Consequently, the following two queries will give the same output:
nas.s1 <- query(ae, "Phonetic == nasal")
nas.s2 <- query(ae, "Phonetic == m | n")We can check that this is true with the function call all(nas.s1 == nas.s2) which checks whether all cells in the two tibbles are identical.
all(nas.s1 == nas.s2)[1] TRUEAs mentioned above, we can add new features with the function add_attrDefLabelGroup(). This takes the same arguments as list_attrDefLabelGroup() above, as well as labelGroupName (the name of the new feature), and labelGroupValues (a vector containing the relevant strings). Below we add a new feature called grave to the Phoneme level which includes all labial and velar consonants:
add_attrDefLabelGroup(ae,
levelName = "Phoneme",
attributeDefinitionName = "Phoneme",
labelGroupName = "grave",
labelGroupValues = c('p', 'b', 'm', 'k', 'g'))We can now use query() to get a list of all segments with the feature grave:
grave.s1 <- query(ae, "Phoneme == grave")
grave.s1 %>% select(-db_uuid)This gives the same result as specifying all grave consonants individually:
grave.s2 <- query(ae, "Phoneme == p | b | m | k | g")
all(grave.s1 == grave.s2)[1] TRUE7.3.3 Sequence queries
So far, we have looked only at simple queries. Anything beyond a simple query requires the query to be enclosed in square brackets [ ], while for simple queries they are optional:
mn1 <- query(ae, "Phoneme == m | n")
mn2 <- query(ae, "[Phoneme == m | n]")
all(mn1 == mn2)[1] TRUEThe results of these two queries are identical! When querying sequences, which we do below, [ ] are no longer optional.
The -> operator is used for finding sequences of annotations. The query [Phonetic == V -> Phonetic == m], for example, finds a sequence in the Phonetic level where the segment V is followed by the segment m.
query(ae, "[Phonetic == V -> Phonetic == m]") %>% select(-db_uuid)By default, sequence queries return the start time of the first segment in the sequence and the end time of the last segment in the sequence (in this case, the start time of the V segment and the end time of the m segment). This behavior can be changed with the “result-modifying” symbol #. In [#Phonetic == V -> Phonetic == m], the # placed before the first portion of the query means that instead of turning V->m sequences, only instances of V which are directly followed by m are returned:
query(ae, "[#Phonetic == V -> Phonetic == m]") %>% select(-db_uuid)Note that here, the labels column only says V rather than V->m, and the end time matches the end of the vowel and not the end of the sequence. Conversely, in [Phonetic == V -> #Phonetic == m], only instances of m which are directly preceded by V are returned:
query(ae, "[Phonetic == V -> #Phonetic == m]") %>% select(-db_uuid)Here, the labels column only says m, and the start time matches the beginning of the consonant.
Only one result-modifying symbol # is allowed per query.
7.3.4 Embedded bracketing
If we want to search for sequences longer than two strings, we can use embedded bracketing. For example, if we want to find sequences of @->n->s, this needs to be phrased as a sequence of @->n and s – in other words, the sequence [Phonetic == @ -> Phonetic == n] needs to be embedded in a larger query like so: [[Phonetic == @ -> Phonetic == n] -> Phonetic == s]:
query(ae, "[[Phonetic == @ -> Phonetic == n] -> Phonetic == s]") %>%
select(-db_uuid)As above, if we want to return only instances of s in @->n->s sequences, we can use a well-placed #:
query(ae, "[[Phonetic == @ -> Phonetic == n] -> #Phonetic == s]") %>%
select(-db_uuid)Any number of queries can be combined. With the following, we look in the Text level for the word offer followed by any two annotations followed by the word resistance:
query(ae, "[[[Text == offer -> Text =~ .*] -> Text =~ .*]
-> Text == resistance]") %>%
select(-db_uuid)7.3.5 Linked levels
The operator ^ is used for queries spanning two linked annotation levels. If we want to find all instances of p at the Phoneme level where the corresponding syllable is stressed (i.e., it is annotated as S at the Syllable level), this can be achieved with the query Phoneme == p ^ Syllable == S:
query(ae, "[Phoneme == p ^ Syllable == S]") %>% select(-db_uuid)Note that the ^ operator does not care about the hierarchical structure of the database; the above query is not just possible because Syllable dominates Phoneme, and if we swap the order of the query, we simply get all instances of stressed syllables that dominate a p at the Phoneme level:
query(ae, "[Syllable == S ^ Phoneme == p]") %>% select(-db_uuid)Embedded bracketing can be used for queries spanning more than two levels. Below we look for any phonetic annotation in a stressed syllable – i.e. [Phonetic =~ .* ^ Syllable == S] – which occurs in the word amongst or beautiful:
query(ae, "[[Phonetic =~ .* ^ Syllable == S] ^
Text == amongst | beautiful]") %>%
select(-db_uuid)7.3.6 Attribute queries
The & operator is used for annotations of a level that is an attribute of another level. For example, in our ae database, Text and Accent are attributes of the Word level. We can check this by using the function list_attributeDefinitions() to find all attributes of Word:
list_attributeDefinitions(ae, level = "Word")Thus, to find all accented words – i.e. words where Accent has the value S (for strong) – we look for any label in Text that also has the value S in Accent, like so:
query(ae, "[Text =~ .* & Accent == S]") %>%
select(-db_uuid)And to find all unaccented (where Accent is W for weak) function words (where Word is F for function):
query(ae, "[Text =~ .* & Accent == W & Word == F]") %>%
select(-db_uuid)We could combine this with a sequence query if we were e.g. interested in finding all unaccented function words that immediately follow a content word (Word == C):
query(ae, "[Word == C -> #Text =~ .* & Accent == W & Word == F]") %>%
select(-db_uuid)7.3.7 Position queries
The EQL has three position functions, Start(x,y), Medial(x,y), and End(x,y). The annotations are returned from y in these cases, where x and y are the two annotation levels that form part of a query. Thus, the following query finds all annotations at the Phoneme level that are initial relative to annotations at the Word level – i.e., word-initial phonemes.
query(ae, "[Start(Word,Phoneme) == TRUE]") %>%
select(-db_uuid)We can find all word-initial and word-medial phonemes by querying whichever phonemes are not word-final, i.e. where the End condition is FALSE:
query(ae, "[End(Word,Phoneme) == FALSE]") %>%
select(-db_uuid)We can combine this with other queries, such as the with the conjunction operator &, to e.g. find all instances of f and S that are word-initial, like so:
query(ae, "[Phoneme == f | S & Start(Word,Phoneme) == TRUE]") %>%
select(-db_uuid)If we e.g. want to find all phonemes in phrase-final syllables, we must combine a position query with a linked query, since Phoneme is dominated by Syllable. So we’d search for any Phoneme where the Syllable is at the end of an Intonational phrase, like so:
query(ae, "[Phoneme =~ .* ^ End(Intonational,Syllable) == TRUE]") %>%
select(-db_uuid)These can be further combined, so we could e.g. specify in the above case that we’re only interested in weak syllables (Syllable == W) like so:
query(ae,
"[Phoneme =~ .* ^ Syllable == W & End(Intonational,Syllable) == TRUE]") %>%
select(-db_uuid)7.3.8 Count queries
Count queries can be done with the Num(x,y) function in combination with a count operator. Possible count operators are ==, != >, >=, <, <=.
Num(x,y) will count the number of annotations at the level y relative to the level x. Unlike the position queries we just saw, which return annotations at the level y, count queries return annotations at the level x. Thus, the following command will find all bisyllabic words (annotation items at the Text level where the number of associated Syllables is exactly 2):
query(ae, "[Num(Text,Syllable) == 2]") %>%
select(-db_uuid)The following query will search for syllables that contain more than 4 phonemes:
query(ae, "[Num(Syllable,Phoneme) > 4]") %>%
select(-db_uuid)Again, this can be combined with other types of queries, i.e. using a domination query to find all syllables in disyllabic words. This is because Num(Text,Syllable) will return annotations at the Text level, i.e. words.
query(ae, "[Syllable =~ .* ^ Num(Text,Syllable) == 2]") %>%
select(-db_uuid)It’s often helpful to build up more complex queries – that involve e.g. counts, positions, and multiple annotation levels – incrementally. This way, you can make sure along the way that you haven’t made a mistake. If, for example, we want to find the final syllable of all trisyllabic words that have a word-final /s/, we could start by finding all trisyllabic words with the count function:
query(ae, "[Num(Text,Syllable) == 3]") %>%
select(-db_uuid)We can add a domination query to find all of the above syllables that contain a phoneme /s/:
query(ae, "[Num(Text,Syllable) == 3 ^ Phoneme == s]") %>%
select(-db_uuid)This can be combined with a position query to ensure that the /s/ is word-final:
query(ae,
"[Num(Text,Syllable) == 3 ^ Phoneme == s & End(Text,Phoneme) == TRUE]") %>%
select(-db_uuid)And to make sure we get the syllable, we can add a further domination query:
query(ae,
"[[#Syllable =~ .* ^ Num(Text,Syllable) == 3]
^ Phoneme == s & End(Text,Phoneme) == TRUE]") %>%
select(-db_uuid)7.4 Functions and operators introduced in this chapter
requery_hier(): Based on an existing segment list generated with aquery(), performs a hierarchical requery based on linked levels.requery_seq(): Based on an existing segment list generated with aquery(), performs a sequential requery to search for adjacent annotations at the same level.list_attrDefLabelGroups(): Lists all defined features / attribute definitions within an annotation level.add_attrDefLabelGroup(): Creates a new feature / attribute definition within an annotation level.==,=: Exact equality operators, returns exactly matching strings!=: Inequality operator, returns everything but exactly matching strings=~: Matching operator, returns partially matching strings!~: Non-matching operator, returns everything but partially matching strings|: “or”-operator, used to combine multiple conditions#: Result-modifying operator, specifies which component of a query to return->: Sequence operator, defines a sequence of annotations to query^: Domination operator, defines a query based on two linked levelsStart(x,y),Medial(x,y),End(x,y): Position operators, defines a query where the position of levelxis defined relative to a dominating levelyNum(x,y): Count operators, defines queries with specific numbers of annotation boundaries in levelxrelative to a dominating levelyby using one of the count operators==,!=,<,>,<=,>=.